
Most engineering organizations now have data on how much they're spending on AI. Far fewer have data on what that spend is producing.
Token consumption is easy to track — your vendor surfaces it automatically, often with alarming detail. Teams report on active seats and token burn rates. Leaders build forecasts around them. CFOs start asking questions. And somewhere in that chain, token spend becomes the unofficial metric for whether AI is working.
The problem with that: token spend is a cost metric. Treating it as a productivity or value signal sends engineering organizations optimizing for the wrong things entirely.
Why do engineering teams keep measuring AI by token usage?
Token usage fills a measurement void. If an organization had a strong value measurement practice before AI arrived, it would have a natural home for AI ROI: did we ship more? Did we ship faster? Did operational burden go down? But most organizations don't have that practice — and AI adoption moved faster than measurement infrastructure could follow.
Ed Quick, a technology executive with experience leading engineering organizations at Cars.com, AWS, and SurveyMonkey, describes how the pattern plays out:

Whether that number represents value delivered is a separate question — and one most organizations haven't built the infrastructure to answer.
There's also a maturity dimension. The early pressure on engineering teams was to adopt AI — get people using it, get seats filled, show progress. The metrics that made sense for adoption (active users, acceptance rates, tokens consumed) were reasonable proxies for that goal. But adoption metrics and outcome metrics are different things, and organizations that haven't made that transition are still optimizing for the wrong target.
AI’s impact on engineering output
Uplevel data shows that AI increases throughput, holds delivery speed mostly flat, and shifts the composition of work in ways that are harder to read than they look.
PR velocity and throughput have climbed consistently across Uplevel customers over the past 18 months. Volume is up, but volume and speed are different metrics.
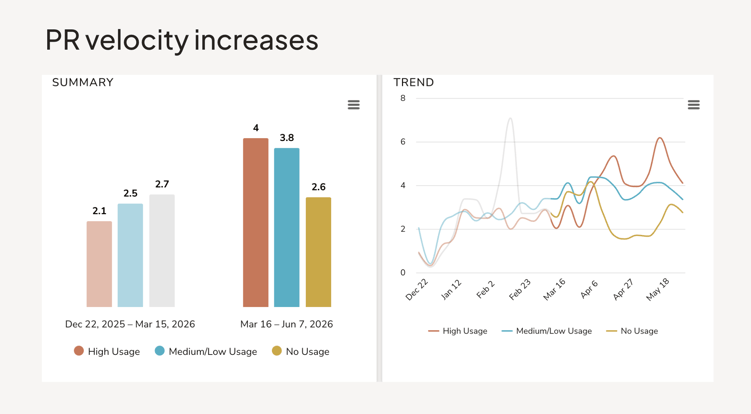
Cycle time — the time it actually takes to move work from start to done — has stayed roughly flat, and in some organizations has gotten marginally worse. More PRs moving doesn't mean work is completing faster. It can mean more work is in flight at once, which creates its own coordination overhead.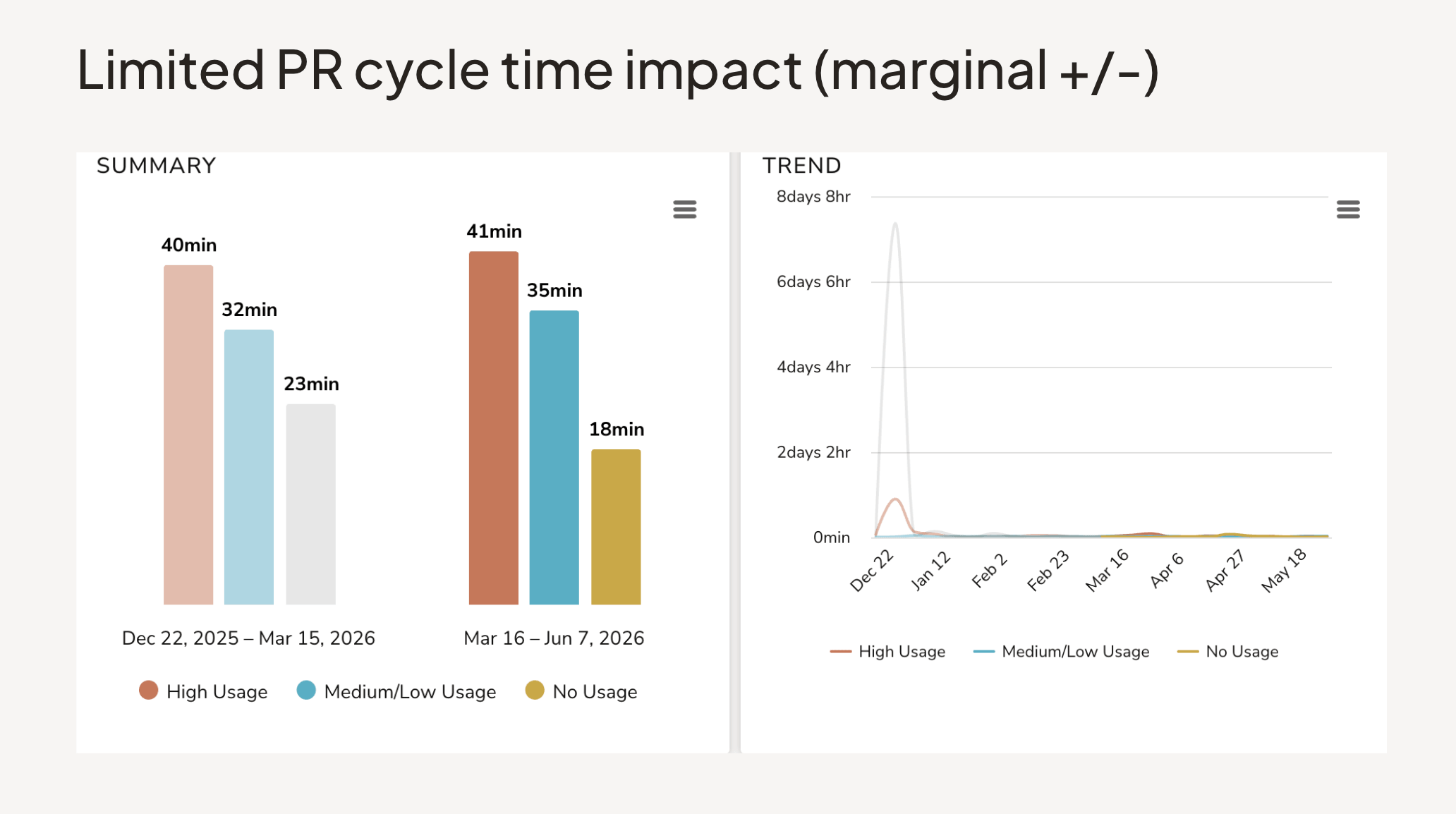
The work composition picture is similarly mixed. We see a modest increase in time spent on new value work — feature development, strategic initiatives — after AI adoption. But in many organizations that gain is counterbalanced by a corresponding rise in “KTLO” operational work. The jury is still out on net impact.
 What this points to is that AI is an amplifier, and what it amplifies depends on what's already in place. Teams with strong CI/CD pipelines, clear backlogs, and good engineering practices tend to get genuine throughput gains. Teams with fragmented workflows, technical debt, and unclear prioritization tend to move faster through the same problems they had before.
What this points to is that AI is an amplifier, and what it amplifies depends on what's already in place. Teams with strong CI/CD pipelines, clear backlogs, and good engineering practices tend to get genuine throughput gains. Teams with fragmented workflows, technical debt, and unclear prioritization tend to move faster through the same problems they had before.
Defining and measuring AI ROI
The organizations that answer this question well start with a written definition of success before touching the data. Ed Quick describes the approach he uses, borrowing from Amazon's working-backwards methodology: write the press release first. Before any AI implementation, define what "done" looks like. What is specifically different? What pain points are gone? What can the team do now that it couldn't do before?
That exercise forces a level of specificity that most AI ROI conversations skip. "We'll be more productive" is not a definition. "Epic lead time drops from six weeks to three, and we ship one major feature per sprint instead of one per quarter" is a clear and measurable outcome.
The who matters as much as the what. Ed's advice get engineers, product partners, and business stakeholders in the room together:
- Engineers understand what's actually painful in the delivery process.
- Product partners know which delays cost the most.
- Stakeholders can tell you which outcomes would move business metrics.
The definition that results from that conversation is a collective one — and collective definitions hold up better when reporting time comes.
Uplevel enterprise transformation consultant MC Johansen also explains that the right metrics depend on how AI is being used, and that varies more than most leaders realize. “A team using AI for code generation has different relevant measures than a team using it for documentation or QA. A single token-based metric collapses all of that into one number, and it loses a lot of meaning.”

What governing AI spend looks like in practice
Token management has a close analogy in cloud cost governance, and the lessons from cloud apply — with some caveats.
Cloud cost optimization took years to build as a discipline. FinOps teams, cost management tooling, and enterprise discount structures all emerged gradually as organizations matured from "plug in an API key and run" to actively managing infrastructure, monitoring, and spend. AI is following the same arc. The opacity of token pricing — how models get swapped behind the scenes, what exactly gets charged and when — maps closely to the early days of cloud billing.
One difference: the vendor incentive problem is starker with AI.
Cloud providers had the same incentives, but the tooling ecosystem matured to counterbalance them — third-party cost managers, native spend dashboards, enterprise agreements with discount structures. AI tooling is getting there. The organizations ahead of the curve are already making the same moves: shifting off direct API pricing into cloud provider implementations, introducing prompt caching, standardizing on a defined set of use cases before expanding.
For teams at different AI maturity levels — some deep into agentic workflows, others still evaluating tools — Ed argues that governance works best as “transparency plus manager” accountability. This means keeping spend visible at the team level and promoting a safe environment for engineers to experiment and fail cheaply. A junior engineer who runs an unbounded context window and suddenly costs the org money is a governance failure — and should be treated as a coaching opportunity.
How one engineering org reached 300% productivity improvement
Ed watched his organization go through the same FOMO-driven AI scramble most large companies experienced — scattered POCs, vendor presentations, a week-long hackathon, 30 things in flight with two worth shipping.
His response was to propose something deliberately smaller: with two teams identified as having a solid product backlog and good PM coverage. A hypothesis: if we focus AI on the most time-consuming steps in our delivery process — ticket creation, initial PR generation, code review — can we see measurable throughput improvement? Ed’s teams defined four or five metrics upfront and dedicated three sprints of runway.
Critically, the experiment was framed around a delivery question: can we ship more value faster? That framing shaped everything, from the metrics chosen and the skills built to the coaching structure.
Quick's team brought in one of the most trusted engineers in the organization to build and embed the shared AI skills library. Sprint one showed promise. Sprint two showed a substantial increase. By sprint three, other teams were asking to join. "Well, this really wasn't an experiment anymore,” Ed recalls. “It was just working."
The cost picture followed. Because the initial teams had built structure around specific, high-value use cases, their token spend was notably lower than the rest of the company despite higher productivity. That gave them leverage to move from third-party API access to their cloud provider's implementation, capturing enterprise discounts and introducing prompt caching. Optimization became possible because the use cases were defined.
Watch the full conversation:
.jpg)
What should engineering leaders tell their CFO about AI spend?
The CFO conversation is coming. If it hasn't happened yet, it will — and showing up without a framework is the wrong move.
Ed's preparation advice: know your numbers, know your trajectory, and know what levers you can pull. That requires a level of internal discipline most engineering orgs haven't built yet, but the payoff for that work goes beyond the budget conversation.
That's a different kind of authority than most engineering leaders are used to claiming. And it comes directly from measurement discipline, not from being first to deploy the most tools.
Amy Carrillo Cotten, Uplevel's director of transformation, argues that leaders who approach AI ROI purely via cost will run a race to the bottom, optimizing spend without ever connecting engineering output to business value. The leaders who earn budget and trust are the ones who've defined what value means for their teams and can show progress against it.
How Uplevel helps engineering teams measure what matters
Token spend tells you what AI costs. Answering what AI is producing requires visibility into the underlying work — how engineers are spending time, how work is flowing through the SDLC, where AI is adding throughput and where it's adding operational burden.
Uplevel integrates data from Jira, GitHub, Slack, Calendar, and AI tools to give engineering leaders a continuous read on work allocation, cycle time, and the ratio of new value work to operational work. That's the data behind the charts in this post. Uplevel combines that continuous measurement with contextual understanding and capability building, so the measurement produces decisions and action.
If you're in the middle of an AI ROI conversation and finding that your current metrics don't support it, schedule a StackUp assessment to see where your engineering system actually stands.
Frequently Asked Questions


![Top Engineering Intelligence Platforms [2026]](https://uplevelteam.com/hubfs/top-engineering-intelligence%20(1).png)