Many engineering leaders track developer velocity to gauge their team’s progress and productivity.
On the surface, the metric seems straightforward — it measures how fast your development team delivers software. Teams using Agile methodologies often quantify it in story points completed per sprint. Higher numbers must mean better performance, right?
Not so much.
According to Goodhart’s Law, when a measure becomes a target, it eventually stops becoming a good measure. If you incentivize your team to maximize a velocity metric, they might find ways to game the system without improving. Considering that we don’t account for factors like code quality and business value within the metric, you rely on it to tell you more than it should.

In this article, we’ll explain how high-performing teams view and measure developer velocity — and time-tested practices to improve it for your organization.
What Makes Measuring Velocity Hard
If it was that easy to measure developer velocity, engineering teams would’ve solved this problem long ago. But the reality is far more complex. In our experience, here are the main reasons why it’s hard to measure this metric:
1. Story points don’t tell the whole story
Story points were designed as a relative measure of effort for estimation purposes — not as a concrete productivity metric. However, engineering teams still treat it as a performance indicator, which leads to problems like:
2. There’s no standard definition
Ask ten engineering leaders how they measure velocity, and you’ll likely get ten different answers:
- Lines of code written (a notoriously misleading metric)
- Number of PRs merged per week
- Features shipped to production
- Story points completed per sprint
- Lead time from commit to deployment
- Bugs fixed per release
A lack of standardization makes it difficult to establish benchmarks. If one team is consistently shipping 20 story points more than another, that difference could be due to factors like team composition and experience levels, codebase complexity, or the nature of the product domain. What works for a platform team is going to be different from what works for a front-end team, for example.
3. Many teams conflate “developer velocity” with performance
The most dangerous challenge is conflating velocity with performance. When engineering leaders use velocity as a performance metric, they create environments where teams game that metric — rushing to complete more story points, optimizing for looking busy rather than delivering value, and avoiding necessary refactoring work that might slow velocity but improve long-term quality.
The question is: does speed matter when quality suffers?
If you’re thinking no, it’s time to take a holistic look at velocity as a metric to make a tangible difference in your team.
How Uplevel Defines Developer Velocity
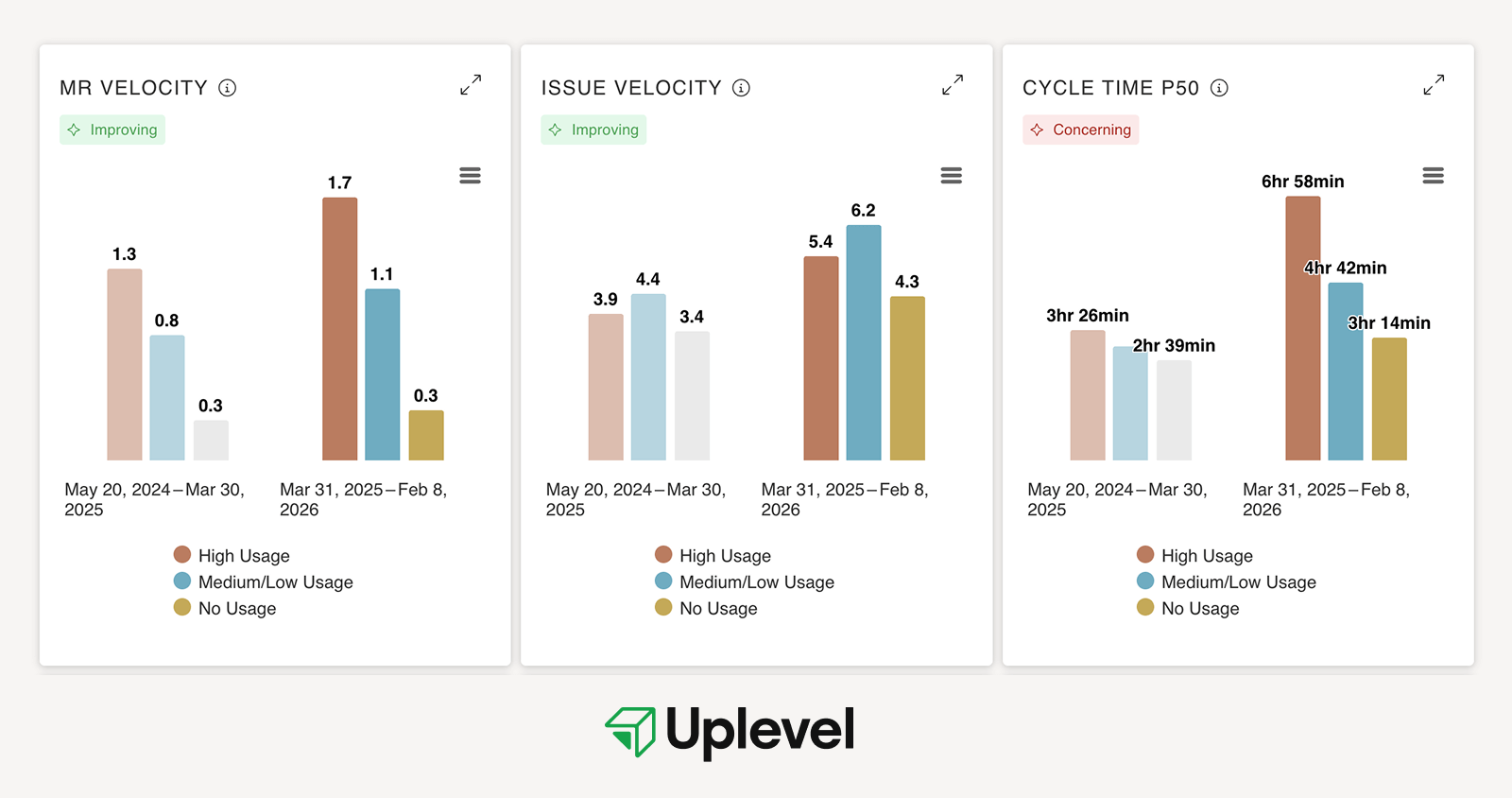
Instead of focusing solely on code commits or PR merges, we define developer velocity as weighted issue throughput over a period, normalized by team size.
By including all completed work items, not just story points, this metric accounts for activities like research spikes, bug investigation, documentation, and design and planning work. We recognize that valuable engineering work doesn’t always result in code.
We also don’t factor in individual velocity metrics out of concern for individual developers — the downstream effect is that collaboration suffers and team cohesion breaks down. Instead, we recommend encouraging collective ownership of outcomes and balanced workloads. Then, you can focus on the actual productivity of your team.
What Factors Impact Velocity?
The problem is rarely “developers need to code faster.” If you want to improve velocity, you have to understand what factors influence the metric:
1. PR cycle time

Pull request (PR) cycle time is often the most visible bottleneck in the development process. Long PR cycle times typically indicate:
- Overly complex changes that are difficult to review
- Insufficient reviewer availability
- Lack of clear review standards
- Dependencies on specific individuals for approval
If your PRs are stuck in review for weeks, your entire development process will be on hold. As a result, developers context-switch to other tasks, in turn creating a cascade of delays.
2. Lead time for changes
Lead time for changes measures how long it takes from code commit to deployment in production. It captures the efficiency of your pipeline, including aspects like code review processes, CI/CD pipeline performance, and deployment approval workflows.

A recent DORA State of DevOps report found that high-efficiency organizations have 127x faster lead times than low-efficiency organizations. If you have a short lead time, you can respond faster to market changes and customer feedback.
3. PR throughput
PR throughput measures how frequently code changes flow through your system. Teams with healthy PR throughput merge code in smaller and more frequent batches and distribute code reviews across the team.
Smaller batches usually mean more scoped work — and easier review. Engineering teams should use a high cadence of such batches to maintain quality and velocity.
If throughput is low, it means your developers are working on large changes, or the review process itself is a bottleneck.
4. Epic throughput
Epic lead time measures how long it takes for an epic to progress from initial planning to completion. You can use it to understand how efficiently your team completes big rocks of work and if your planning process aligns with delivery capabilities.
A common pattern in inefficient teams is the “end-of-quarter crunch.” There’s a tendency to push the completion of multiple epics together — at the expense of quality.
5. Work in progress (WIP)
WIP is the number of items a team works on that simultaneously impact their velocity. If they’re working on too many items concurrently, it could lead to higher context switching, longer task story points, and higher cognitive load and stress.
According to Kevin Madore, a neuroscientist at Stanford University, multitasking has massive “task switch costs.” Every time you switch between tasks, its accuracy rate reduces — chipping away at your working and long-term memory.
That’s why it’s a good rule of thumb to keep it between one to two items per developer.
6. Epic lead time

Epic lead time measures how long it takes for an epic to progress from initial planning to completion. You can use this metric to improve your planning process and accurately forecast delivery timelines. Long epic lead times tell you that:
- Your estimation practices aren’t hitting the mark
- Your work breakdown structures are ineffective
- Your team might be shifting priorities and scope often
- Your team hasn’t accounted for dependencies like external approvals or lengthy code integration processes
In short: you haven’t accounted for every task, process, and dependency in your development workflow. You’ll have to review the current way of doing things and pinpoint what’s slowing you down. For example, if you’re used to planning multiple quarters in advance, it’s easy to miss the smaller (or even unknown) dependencies. In this case, relatively shorter planning sprints force you to take a closer look.
How Can Engineering Leaders Ship Faster?
Now that you know what’s impacting developer velocity, let’s look at how you can improve it:
1. Identify and address WIP issues first
Start by creating firm WIP limits — preferably one to two items per developer. Make it a team norm to move items from “To do” to “Done” before taking on additional work. This way, their tasks shouldn’t take longer than a day or to finish and if they do, try to understand what’s preventing that.
Also, talk to your team and see who has the highest volume of WIPs and review why some things continue to stay in flight. This should give you a better idea of any dependencies or unclear requirements that are blocking progress.
If tasks take more than two days to finish, consider breaking them down into smaller pieces. The reduced scope makes the PR sizes smaller which improves your review time and quality. And make sure you use kanban boards or dashboards to make the progress visible. This way, you can see what’s happening in real time and implement guardrails around this process.
2. Take a good look at your planning process
Your epic lead times tell you how good (or bad) your planning process is. If it’s too long, you need to make changes. Here are a few recommendations:
3. Optimize your code review and deployment workflow
PR cycle time and lead time for changes often represent the most visible bottlenecks. That’s why you need to set team norms and distribute the review workload across the entire team to avoid burdening them.
Also, keep your PRs small so that they are easier to review. You can review PRs that were merged and see common patterns in them. If the team’s PR complexity exceeds 20%, your reviewers might find them harder to review.
.png?width=1065&height=411&name=engineering%20intelligence%20complex%20prs%20(1).png)
If your deployment phase is long, review what processes exist — and identify the bottlenecks. It could be that your team is doing large weekly/monthly releases. In this case, use trunk-based development to frequently integrate code with the main branch.
4. Account for the hidden work that impacts velocity
Everything your team does won’t show in traditional velocity metrics. So, you need to plan for interruptions such as:
- Meetings
- Found or reactionary work
- Slack pings
- Email notifications
Ideally, you’re tracking using an engineering intelligence tool to make accurate estimates and identify teams that are at risk of performance issues due to burnout. Once you do, talk to your team and audit these interruptions.

For example, if your team’s spending too much time in meetings, intentionally consolidate these meetings or remove the unnecessary ones. On the other hand, if they’re interrupted by too many notifications, find ways to block notifications during deep work periods or adjust notification settings. The goal is to remove whatever doesn’t add value.
5. Restructure your team and communication framework
You also need to consider how your team is doing things — not just what they’re doing. Projects usually get slowed down due to:
- Building large teams
- Grouping teams based on irrelevant parameters
- Complicating communication structure
When you have large teams, it’s hard to understand what individual developers are working on and how that cohesively ties back into the team’s goals. You also won’t be able to parse out the true dependencies because different developers might be dealing with different kinds of interruptions or priorities. That’s why you should consider trimming the size of your team.
For instance, you can use Amazon’s two-pizze rule to create teams. The idea is that if your team needs more than two pizzas in a single meal or meeting, it’s too big.

Reducing team size makes it easier to communicate. You can use Conway’s Law to structure teams and set communication frameworks. For instance, structure teams around products or capabilities instead of level of experience/seniority. This way, they don’t waste time trying to get answers from different teams and you can assign work easily.

Developers who find their work more engaging feel 30% more productive. Considering that an organization’s culture plays a role in how work is structured and assigned, these factors play a huge role.
6. Create a psychologically safe environment
You can’t create a safe environment for your team when developers are concerned about velocity being used as a performance metric. It just incentivizes speed over quality, leading to a domino of problems. Understand what developer velocity truly encompasses and then use it to evaluate team performance.
And encourage your developers to speak their minds. Maybe they bit off more than they could chew the last sprint, or they’re dealing with too many unrelated interruptions. You won’t know unless you give them the space to speak up — without negative consequences.
However, it’s also important to note that this ultimately ties back to the organizational culture, not individual developers or development teams. This approach is more about creating the right systems, like blameless retros where you ask questions to learn more about what went wrong and not who’s to blame. When you approach the impact on velocity this way, your team won’t get defensive and you can get to the root of the problem and fix it.
Developer Velocity Is a Sociotechnical Challenge — Not Just a Technical One
You’re missing the larger picture if your organization fixates on velocity metrics like story points complete or deployment frequency. As Goodhart’s Law indicates, the metric will stop becoming a good measure. As a result, you’ll optimize for the metric, not the outcomes that matter.
Also, velocity is a means, not the end. Your ultimate goal is to identify if your team continuously delivers value to users and the business. This requires a mindset shift from “How can we increase velocity?” to “How can we create an environment where teams can consistently deliver maximum value to our users?”
High developer velocity means nothing if it doesn’t translate to products that users love and teams that thrive.